
Bringing Azure Data into ClickHouse
Microsoft Azure offers a wide range of tools to store, transform, and analyze data. However, in many scenarios, ClickHouse can provide significantly better performance for low-latency querying and processing of very large datasets. In addition, ClickHouse's columnar storage and compression can greatly reduce the cost of querying large volumes of analytical data compared to general-purpose Azure databases.
In this article, we will explore two ways to ingest data from Microsoft Azure into ClickHouse. The first method, and likely the easiest, involves using ClickHouse's azureBlobStorage Table Function to transfer data directly from Azure Blob Storage. The second method uses the ClickHouse HTTP interface as a data source within Azure Data Factory, allowing you to copy data or use it in data flow activities as part of your pipelines.
Using ClickHouse's azureBlobStorage table function
This is one of the most efficient and straightforward ways to copy data from Azure Blob Storage or Azure Data Lake Storage into ClickHouse. With this table function, you can instruct ClickHouse to connect directly to Azure storage and read data on demand.
It provides a table-like interface that allows you to select, insert, and filter data directly from the source. The function is highly optimized and supports many widely used file formats, including CSV, JSON, Parquet, Arrow, TSV, ORC, Avro, and more.
In this section, we'll walk through a simple startup guide for transferring data from Azure Blob Storage to ClickHouse, along with important considerations for using this function effectively. For more details and advanced options, refer to the official documentation: azureBlobStorage Table Function documentation page
Acquiring Azure Blob Storage Access Keys
To allow ClickHouse to access your Azure Blob Storage, you'll need a connection string with an access key.
-
In the Azure portal, navigate to your Storage Account.
-
In the left-hand menu, select Access keys under the Security + networking section.
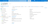
-
Choose either key1 or key2, and click the Show button next to the Connection string field.
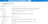
-
Copy the connection string — you'll use this as a parameter in the azureBlobStorage table function.
Querying the data from Azure Blob Storage
Open your preferred ClickHouse query console — this can be the ClickHouse Cloud web interface, the ClickHouse CLI client, or any other tool you use to run queries. Once you have both the connection string and your ClickHouse query console ready, you can start querying data directly from Azure Blob Storage.
In the following example, we query all the data stored in JSON files located in a container named data-container:
If you'd like to copy that data into a local ClickHouse table (e.g., my_table),
you can use an INSERT INTO ... SELECT statement:
This allows you to efficiently pull external data into ClickHouse without needing intermediate ETL steps.
A simple example using the Environmental Sensors Dataset
As an example we will download a single file from the Environmental Sensors Dataset.
-
Download a sample file from the Environmental Sensors Dataset
-
In the Azure Portal, create a new storage account if you don't already have one.
Make sure that Allow storage account key access is enabled for your storage account, otherwise you will not be able to use the account keys to access the data.
-
Create a new container in your storage account. In this example, we name it sensors. You can skip this step if you're using an existing container.
-
Upload the previously downloaded
2019-06_bmp180.csv.zstfile to the container. -
Follow the steps described earlier to obtain the Azure Blob Storage connection string.
Now that everything is set up, you can query the data directly from Azure Blob Storage:
- To load the data into a table, create a simplified version of the
schema used in the original dataset:
For more information on configuration options and schema inference when querying external sources like Azure Blob Storage, see Automatic schema inference from input data
- Now insert the data from Azure Blob Storage into the sensors table:
Your sensors table is now populated with data from the 2019-06_bmp180.csv.zst
file stored in Azure Blob Storage.
Additional Resources
This is just a basic introduction to using the azureBlobStorage function. For more advanced options and configuration details, please refer to the official documentation:
- azureBlobStorage Table Function
- Formats for Input and Output Data
- Automatic schema inference from input data
Using ClickHouse HTTP Interface in Azure Data Factory
The azureBlobStorage Table Function is a fast and convenient way to ingest data from Azure Blob Storage into ClickHouse. Using it may however not always be suitable for the following reasons:
- Your data might not be stored in Azure Blob Storage — for example, it could be in Azure SQL Database, Microsoft SQL Server, or Cosmos DB.
- Security policies might prevent external access to Blob Storage altogether — for example, if the storage account is locked down with no public endpoint.
In such scenarios, you can use Azure Data Factory together with the ClickHouse HTTP interface to send data from Azure services into ClickHouse.
This method reverses the flow: instead of having ClickHouse pull the data from Azure, Azure Data Factory pushes the data to ClickHouse. This approach typically requires your ClickHouse instance to be accessible from the public internet.
It is possible to avoid exposing your ClickHouse instance to the internet by using Azure Data Factory's Self-hosted Integration Runtime. This setup allows data to be sent over a private network. However, it's beyond the scope of this article. You can find more information in the official guide: Create and configure a self-hosted integration runtime
Turning ClickHouse into a REST service
Azure Data Factory supports sending data to external systems over HTTP in JSON format. We can use this capability to insert data directly into ClickHouse using the ClickHouse HTTP interface. You can learn more in the ClickHouse HTTP Interface documentation.
For this example, we only need to specify the destination table, define the input data format as JSON, and include options to allow more flexible timestamp parsing.
To send this query as part of an HTTP request, you simply pass it as a URL-encoded string to the query parameter in your ClickHouse endpoint:
Azure Data Factory can handle this encoding automatically using its built-in
encodeUriComponent function, so you don't have to do it manually.
Now you can send JSON-formatted data to this URL. The data should match the
structure of the target table. Here’s a simple example using curl, assuming a
table with three columns: col_1, col_2, and col_3.
You can also send a JSON array of objects, or JSON Lines (newline-delimited
JSON objects). Azure Data Factory uses the JSON array format, which works
perfectly with ClickHouse’s JSONEachRow input.
As you can see, for this step you don’t need to do anything special on the ClickHouse side. The HTTP interface already provides everything needed to act as a REST-like endpoint — no additional configuration required.
Now that we’ve made ClickHouse behave like a REST endpoint, it's time to configure Azure Data Factory to use it.
In the next steps, we'll create an Azure Data Factory instance, set up a Linked Service to your ClickHouse instance, define a Dataset for the REST sink, and create a Copy Data activity to send data from Azure to ClickHouse.
Creating an Azure Data Factory instance
This guide assumes that you have access to Microsoft Azure account, and you already have configured a subscription and a resource group. If you have an Azure Data Factory already configured, then you can safely skip this step and move to the next one using your existing service.
-
Log in to the Microsoft Azure Portal and click Create a resource.
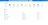
-
In the Categories pane on the left, select Analytics, then click on Data Factory in the list of popular services.
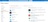
-
Select your subscription and resource group, enter a name for the new Data Factory instance, choose the region and leave the version as V2.
-
Click Review + Create, then click Create to launch the deployment.

Once the deployment completes successfully, you can start using your new Azure Data Factory instance.
Creating a new REST-Based linked service
-
Log in to the Microsoft Azure Portal and open your Data Factory instance.
-
On the Data Factory overview page, click Launch Studio.
-
In the left-hand menu, select Manage, then go to Linked services, and click + New to create a new linked service.
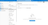
-
In the New linked service search bar, type REST, select REST, and click Continue to create a REST connector instance.
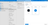
-
In the linked service configuration pane enter a name for your new service, click the Base URL field, then click Add dynamic content (this link only appears when the field is selected).
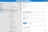
-
In the dynamic content pane you can create a parameterized URL, which allows you to define the query later when creating datasets for different tables — this makes the linked service reusable.
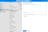
-
Click the "+" next to the filter input and add a new parameter, name it
pQuery, set the type to String, and set the default value toSELECT 1. Click Save.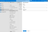
-
In the expression field, enter the following and click OK. Replace
your-clickhouse-url.comwith the actual address of your ClickHouse instance.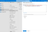
-
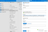
Back in the main form select Basic authentication, enter the username and password used to connect to your ClickHouse HTTP interface, click Test connection. If everything is configured correctly, you’ll see a success message.
-
Click Create to finalize the setup.
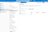
You should now see your newly registered REST-based linked service in the list.
Creating a new dataset for the ClickHouse HTTP Interface
Now that we have a linked service configured for the ClickHouse HTTP interface, we can create a dataset that Azure Data Factory will use to send data to ClickHouse.
In this example, we'll insert a small portion of the Environmental Sensors Data.
-
Open the ClickHouse query console of your choice — this could be the ClickHouse Cloud web UI, the CLI client, or any other interface you use to run queries — and create the target table:
-
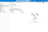
In Azure Data Factory Studio, select Author in the left-hand pane. Hover over the Dataset item, click the three-dot icon, and choose New dataset.
-
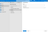
In the search bar, type REST, select REST, and click Continue. Enter a name for your dataset and select the linked service you created in the previous step. Click OK to create the dataset.
-
You should now see your newly created dataset listed under the Datasets section in the Factory Resources pane on the left. Select the dataset to open its properties. You'll see the
pQueryparameter that was defined in the linked service. Click the Value text field. Then click Add dynamic content.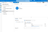
-
In the pane that opens, paste the following query:
dangerAll single quotes
'in the query must be replaced with two single quotes''. This is required by Azure Data Factory's expression parser. If you don't escape them, you may not see an error immediately — but it will fail later when you try to use or save the dataset. For example,'best_effort'must be written as''best_effort''.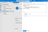
-
Click OK to save the expression. Click Test connection. If everything is configured correctly, you’ll see a Connection successful message. Click Publish all at the top of the page to save your changes.
Setting up an example dataset
In this example, we will not use the full Environmental Sensors Dataset, but just a small subset available at the Sensors Dataset Sample.
To keep this guide focused, we won't go into the exact steps for creating the source dataset in Azure Data Factory. You can upload the sample data to any storage service of your choice — for example, Azure Blob Storage, Microsoft SQL Server, or even a different file format supported by Azure Data Factory.
Upload the dataset to your Azure Blob Storage (or another preferred storage service), Then, in Azure Data Factory Studio, go to the Factory Resources pane. Create a new dataset that points to the uploaded data. Click Publish all to save your changes.
Creating a Copy Activity to transfer data to ClickHouse
Now that we've configured both the input and output datasets, we can set up a
Copy Data activity to transfer data from our example dataset into the
sensors table in ClickHouse.
-
Open Azure Data Factory Studio, go to the Author tab. In the Factory Resources pane, hover over Pipeline, click the three-dot icon, and select New pipeline.
-
In the Activities pane, expand the Move and transform section and drag the Copy data activity onto the canvas.
-
Select the Source tab, and choose the source dataset you created earlier.
-
Go to the Sink tab and select the ClickHouse dataset created for your sensors table. Set Request method to POST. Ensure HTTP compression type is set to None.
dangerHTTP compression does not work correctly in Azure Data Factory's Copy Data activity. When enabled, Azure sends a payload consisting of zero bytes only — likely a bug in the service. Be sure to leave compression disabled.
infoWe recommend keeping the default batch size of 10,000, or even increasing it further. For more details, see Selecting an Insert Strategy / Batch inserts if synchronous for more details.
-
Click Debug at the top of the canvas to run the pipeline. After a short wait, the activity will be queued and executed. If everything is configured correctly, the task should finish with a Success status.
-
Once complete, click Publish all to save your pipeline and dataset changes.